Meet NetActuate at All Things Open 2025 in Raleigh Oct 13-14!
Explore

Meet NetActuate at All Things Open 2025 in Raleigh Oct 13-14!


Everywhere you look, AI is transforming everything we do. From in-depth analysis to conversational interactions, innovative and powerful new uses for AI are uncovered practically every day. This is driving a boom in AI app development, as well as adding new AI features to existing applications. According to IDC, the global market for AI software will grow to nearly $251 billion by 2027.
As these applications get more powerful and interactive, it becomes more essential to deliver them at the edge. Ensuring a seamless user experience for a powerful, interactive AI app requires latency to be as low as possible. One critical part of an AI edge delivery strategy should be BGP anycast.
When combined with high-performance hardware, anycast will keep your AI application fast, reliable, and resilient – all while ensuring end users get the best possible experience.
The fastest-growing type of AI applications in the market today are generative AI. GenAI apps learn, discover, as well as make recommendations and predictions in response to user requests. The creation and launch of AI platforms is also booming, expecting to increase by nearly 36% in the next year.
Existing applications are also increasingly incorporating AI into their feature set. By 2026, Gartner predicts that 30% of new applications will use AI to drive personalized adaptive user interfaces, up from less than 5% today.
From generative AI to existing applications with new AI features, one thing is for certain: they are all far more resource intensive than other application types. AI applications require a lot of GPU power, depend on vast databases and storage, and often need high-bandwidth connectivity to other AI services in order to function.
With AI, milliseconds can make a significant difference in the user experience.
From a chatbot responding to a sales inquiry, or a recommendation system delivering real-time suggestions, latency must be kept extremely low. Reliability is also key, as outages or service disruptions can lead to lost business and revenue faster than ever before.
Even AI apps that process, monitor, and analyze data will rely on fast connectivity. The data sources are often so large that AI apps must deploy near their data sources as well as their end users. Numerous challenges such as cost, security, and latency will need to be taken into consideration, especially since networks are currently optimized for downloading, not uploading.
With such high requirements for low latency and high performance, anycast becomes a clear choice for AI application delivery. By leveraging anycast in your AI delivery, you can simplify your overall network architecture, ensure the highest possible performance for each end user, improve reliability, and enable rapid scaling.
So just how does anycast specifically improve application delivery for AI? Some of the key benefits of anycast include:
With anycast, every available application server is reachable via a single IP address. When a user sends a request to that IP address, BGP anycast routing sends their request to the nearest server to them on the network. This often, though not always, means it will be one physically closest to them as well.
When every incoming request is handled by the server nearest to them on the network, it minimizes the time it takes for data to travel back and forth. This reduced latency optimizes performance for applications like image recognition, natural language processing, and autonomous systems, where real-time decisions are a feature of the application itself.
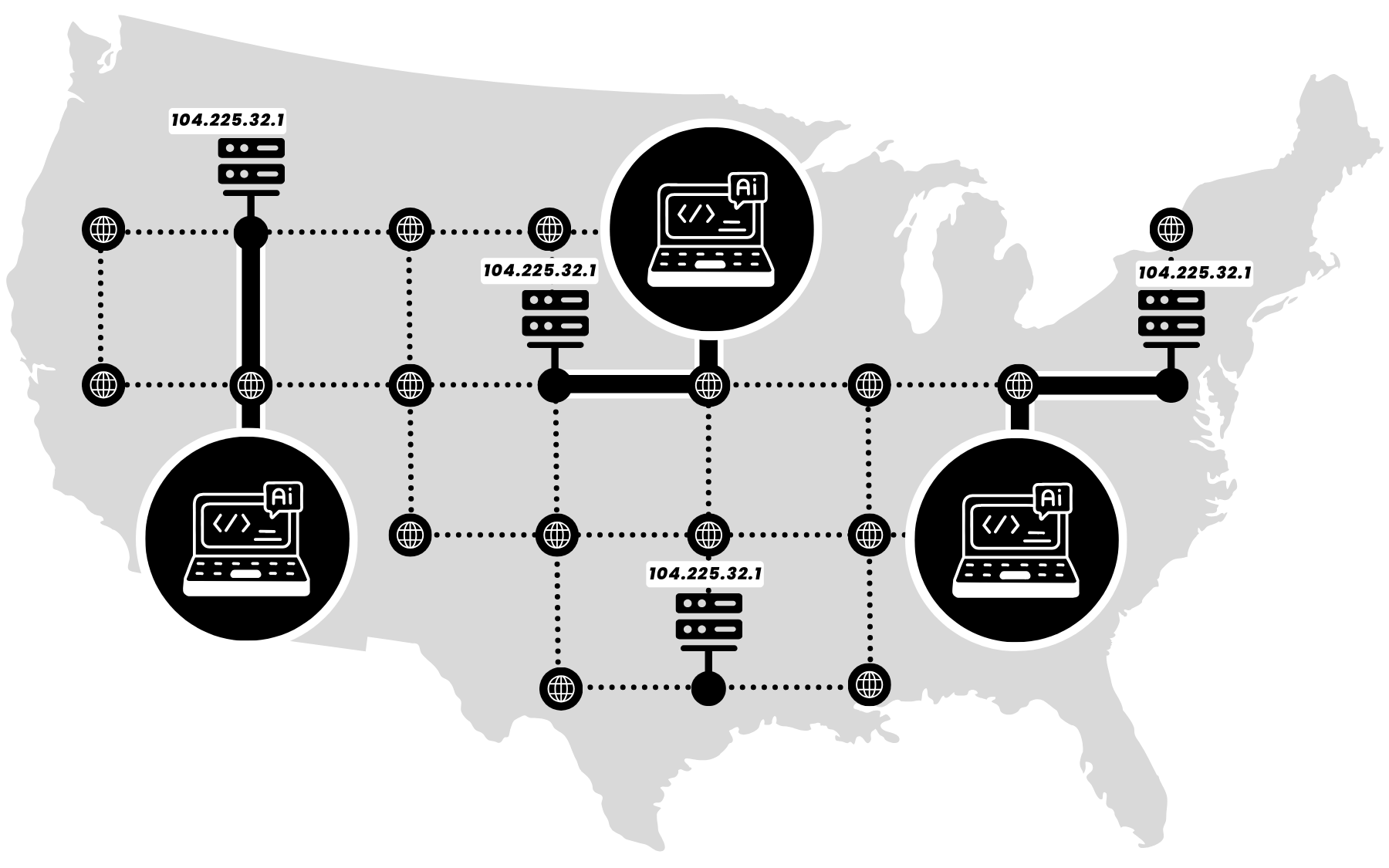
As anycast sends each incoming request to the nearest available server, it automatically distributes traffic across a footprint. This allows for load balancing without extra tools or configurations. Any single server is also much less likely to get overloaded and experience slowdowns or delays.
The fact that each server is broadcasting the same IP address can improve reliability as well. If a location does go offline or becomes unreachable, requests are simply sent to the next nearest server. This greatly minimizes the risk of downtime and ensures uninterrupted service.
If an AI application gains popularity quickly, or is heavily leveraged during specific times, it can experience unpredictable spikes in traffic. However, with anycast, incoming requests can be serviced by the nearest server with available capacity. When many requests to access the AI application come in rapidly, the anycast intelligently distributes them across the available servers. This helps prevent overload and ensures a consistent user experience.
Anycast also makes it easy to quickly expand your footprint. To add new servers, you simply need to bring them online and announce the anycast IP. Once announced, the new servers can immediately begin servicing incoming requests to keep up increased demand. This also makes it easy to adjust your footprint if usage isn’t as high in one region, but you need additional resources in another.
The needs of today’s growing market of AI applications relies on low latency and high availability across often large footprints of servers. By incorporating anycast into your overall application delivery strategy, you can meet both of those requirements, as well as make it simpler to scale and optimize your footprint.
If you’d like to learn more about how anycast can help with your AI application delivery, schedule a call with an anycast expert at NetActuate today.

Deploy across 45+ global locations on one of the world’s largest networks, engineered for performance, resiliency, and efficient scaling without the risk of downtime or runaway costs.







